Next: 11.2 Counting Sort and Up: 11. Sorting Algorithms Previous: 11. Sorting Algorithms Contents Index
In this section, we present three sorting algorithms: merge-sort,
quicksort, and heap-sort. Each of these algorithms takes an input array
![]() and sorts the elements of
and sorts the elements of
![]() into non-decreasing order in
into non-decreasing order in
![]() (expected) time. These algorithms are all comparison-based.
Their second argument,
(expected) time. These algorithms are all comparison-based.
Their second argument,
![]() , is a Comparator
that implements
the
, is a Comparator
that implements
the
![]() method. These algorithms don't care what type
of data is being sorted; the only operation they do on the data is
comparisons using the
method. These algorithms don't care what type
of data is being sorted; the only operation they do on the data is
comparisons using the
![]() method. Recall, from Section 1.2.4,
that
method. Recall, from Section 1.2.4,
that
![]() returns a negative value if
returns a negative value if
![]() , a positive
value if
, a positive
value if
![]() , and zero if
, and zero if
![]() .
.
The merge-sort algorithm is a classic example of recursive divide
and conquer:
If the length of
![]() is at most 1, then
is at most 1, then
![]() is already
sorted, so we do nothing. Otherwise, we split
is already
sorted, so we do nothing. Otherwise, we split
![]() into two halves,
into two halves,
![]() and
and
![]() .
We recursively sort
.
We recursively sort
![]() and
and
![]() , and then we merge (the now sorted)
, and then we merge (the now sorted)
![]() and
and
![]() to get our fully sorted array
to get our fully sorted array
![]() :
:
<T> void mergeSort(T[] a, Comparator<T> c) {
if (a.length <= 1) return;
T[] a0 = Arrays.copyOfRange(a, 0, a.length/2);
T[] a1 = Arrays.copyOfRange(a, a.length/2, a.length);
mergeSort(a0, c);
mergeSort(a1, c);
merge(a0, a1, a, c);
}
An example is shown in Figure 11.1.
Compared to sorting, merging the two sorted arrays
![]() and
and
![]() is
fairly easy. We add elements to
is
fairly easy. We add elements to
![]() one at a time. If
one at a time. If
![]() or
or
![]() is empty, then we add the next elements from the other (non-empty)
array. Otherwise, we take the minimum of the next element in
is empty, then we add the next elements from the other (non-empty)
array. Otherwise, we take the minimum of the next element in
![]() and
the next element in
and
the next element in
![]() and add it to
and add it to
![]() :
:
<T> void merge(T[] a0, T[] a1, T[] a, Comparator<T> c) {
int i0 = 0, i1 = 0;
for (int i = 0; i < a.length; i++) {
if (i0 == a0.length)
a[i] = a1[i1++];
else if (i1 == a1.length)
a[i] = a0[i0++];
else if (compare(a0[i0], a1[i1]) < 0)
a[i] = a0[i0++];
else
a[i] = a1[i1++];
}
}
Notice that the
To understand the running-time of merge-sort, it is easiest to think
of it in terms of its recursion tree. Suppose for now that
![]() is a
power of two, so that
is a
power of two, so that
![]() , and
, and
![]() is an integer.
Refer to Figure 11.2. Merge-sort turns the problem of
sorting
is an integer.
Refer to Figure 11.2. Merge-sort turns the problem of
sorting
![]() elements into two problems, each of sorting
elements into two problems, each of sorting
![]() elements.
These two subproblem are then turned into two problems each, for a total
of four subproblems, each of size
elements.
These two subproblem are then turned into two problems each, for a total
of four subproblems, each of size
![]() . These four subproblems become eight
subproblems, each of size
. These four subproblems become eight
subproblems, each of size
![]() , and so on. At the bottom of this process,
, and so on. At the bottom of this process,
![]() subproblems, each of size two, are converted into
subproblems, each of size two, are converted into
![]() problems,
each of size one. For each subproblem of size
problems,
each of size one. For each subproblem of size
![]() , the time
spent merging and copying data is
, the time
spent merging and copying data is
![]() . Since there are
. Since there are ![]() subproblems of size
subproblems of size
![]() , the total time spent working on problems
of size
, the total time spent working on problems
of size ![]() , not counting recursive calls, is
, not counting recursive calls, is
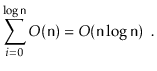
The proof of the following theorem is based on preceding analysis,
but has to be a little more careful to deal with the cases where
![]() is not a power of 2.
is not a power of 2.
Merging two sorted lists of total length
![]() requires at most
requires at most
![]() comparisons. Let
comparisons. Let
![]() denote the maximum number of comparisons performed by
denote the maximum number of comparisons performed by
![]() on an array
on an array
![]() of length
of length
![]() . If
. If
![]() is even, then we apply the inductive hypothesis to
the two subproblems and obtain
is even, then we apply the inductive hypothesis to
the two subproblems and obtain
The quicksort algorithm is another classic divide and conquer algorithm. Unlike merge-sort, which does merging after solving the two subproblems, quicksort does all of its work upfront.
Quicksort is simple to describe: Pick a random pivot element,
![]() , from
, from
![]() ; partition
; partition
![]() into the set of elements less than
into the set of elements less than
![]() , the
set of elements equal to
, the
set of elements equal to
![]() , and the set of elements greater than
, and the set of elements greater than
![]() ;
and, finally, recursively sort the first and third sets in this partition.
An example is shown in Figure 11.3.
;
and, finally, recursively sort the first and third sets in this partition.
An example is shown in Figure 11.3.
<T> void quickSort(T[] a, Comparator<T> c) {
quickSort(a, 0, a.length, c);
}
<T> void quickSort(T[] a, int i, int n, Comparator<T> c) {
if (n <= 1) return;
T x = a[i + rand.nextInt(n)];
int p = i-1, j = i, q = i+n;
// a[i..p]<x, a[p+1..q-1]??x, a[q..i+n-1]>x
while (j < q) {
int comp = compare(a[j], x);
if (comp < 0) { // move to beginning of array
swap(a, j++, ++p);
} else if (comp > 0) {
swap(a, j, --q); // move to end of array
} else {
j++; // keep in the middle
}
}
// a[i..p]<x, a[p+1..q-1]=x, a[q..i+n-1]>x
quickSort(a, i, p-i+1, c);
quickSort(a, q, n-(q-i), c);
}
All of this is done in place, so that instead of making copies of
subarrays being sorted, the
At the heart of the quicksort algorithm is the in-place partitioning
algorithm. This algorithm, without using any extra space, swaps elements
in
![]() and computes indices
and computes indices
![]() and
and
![]() so that
so that
![$\displaystyle \ensuremath{\mathtt{a[i]}} \begin{cases}
{}< \ensuremath{\mathtt...
...htt{q}}\le \ensuremath{\mathtt{i}} \le \ensuremath{\mathtt{n}}-1$}
\end{cases}$](img4150.png)
Quicksort is very closely related to the random binary search trees
studied in Section 7.1. In fact, if the input to quicksort consists
of
![]() distinct elements, then the quicksort recursion tree is a random
binary search tree. To see this, recall that when constructing a random
binary search tree the first thing we do is pick a random element
distinct elements, then the quicksort recursion tree is a random
binary search tree. To see this, recall that when constructing a random
binary search tree the first thing we do is pick a random element
![]() and
make it the root of the tree. After this, every element will eventually
be compared to
and
make it the root of the tree. After this, every element will eventually
be compared to
![]() , with smaller elements going into the left subtree
and larger elements into the right.
, with smaller elements going into the left subtree
and larger elements into the right.
In quicksort, we select a random element
![]() and immediately compare
everything to
and immediately compare
everything to
![]() , putting the smaller elements at the beginning of
the array and larger elements at the end of the array. Quicksort then
recursively sorts the beginning of the array and the end of the array,
while the random binary search tree recursively inserts smaller elements
in the left subtree of the root and larger elements in the right subtree
of the root.
, putting the smaller elements at the beginning of
the array and larger elements at the end of the array. Quicksort then
recursively sorts the beginning of the array and the end of the array,
while the random binary search tree recursively inserts smaller elements
in the left subtree of the root and larger elements in the right subtree
of the root.
The above correspondence between random binary search trees and quicksort means that we can translate Lemma 7.1 to a statement about quicksort:
A little summing up of harmonic numbers gives us the following theorem about the running time of quicksort:
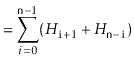 |
||
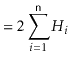 |
||
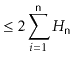 |
||
Theorem 11.3 describes the case where the elements being sorted are
all distinct. When the input array,
![]() , contains duplicate elements,
the expected running time of quicksort is no worse, and can be even
better; any time a duplicate element
, contains duplicate elements,
the expected running time of quicksort is no worse, and can be even
better; any time a duplicate element
![]() is chosen as a pivot, all
occurrences of
is chosen as a pivot, all
occurrences of
![]() get grouped together and do not take part in either
of the two subproblems.
get grouped together and do not take part in either
of the two subproblems.
The heap-sort algorithm is another in-place sorting algorithm.
Heap-sort uses the binary heaps discussed in Section 10.1.
Recall that the BinaryHeap data structure represents a heap using
a single array. The heap-sort algorithm converts the input array
![]() into a heap and then repeatedly extracts the minimum value.
into a heap and then repeatedly extracts the minimum value.
More specifically, a heap stores
![]() elements in an array,
elements in an array,
![]() , at array locations
, at array locations
![]() with the smallest value stored at the root,
with the smallest value stored at the root,
![]() . After transforming
. After transforming
![]() into a BinaryHeap, the heap-sort
algorithm repeatedly swaps
into a BinaryHeap, the heap-sort
algorithm repeatedly swaps
![]() and
and
![]() , decrements
, decrements
![]() , and
calls
, and
calls
![]() so that
so that
![]() once again are
a valid heap representation. When this process ends (because
once again are
a valid heap representation. When this process ends (because
![]() )
the elements of
)
the elements of
![]() are stored in decreasing order, so
are stored in decreasing order, so
![]() is reversed
to obtain the final sorted order.11.1Figure 11.4 shows an example of the execution of
is reversed
to obtain the final sorted order.11.1Figure 11.4 shows an example of the execution of
![]() .
.
![\includegraphics[scale=0.90909]{figs/heapsort}](img4198.png)
|
<T> void sort(T[] a, Comparator<T> c) {
BinaryHeap<T> h = new BinaryHeap<T>(a, c);
while (h.n > 1) {
h.swap(--h.n, 0);
h.trickleDown(0);
}
Collections.reverse(Arrays.asList(a));
}
A key subroutine in heap sort is the constructor for turning
an unsorted array
![]() into a heap. It would be easy to do this
in
into a heap. It would be easy to do this
in
![]() time by repeatedly calling the BinaryHeap
time by repeatedly calling the BinaryHeap
![]() method, but we can do better by using a bottom-up algorithm.
Recall that, in a binary heap, the children of
method, but we can do better by using a bottom-up algorithm.
Recall that, in a binary heap, the children of
![]() are stored at
positions
are stored at
positions
![]() and
and
![]() . This implies that the elements
. This implies that the elements
![]() have no children. In other
words, each of
have no children. In other
words, each of
![]() is a sub-heap
of size 1. Now, working backwards, we can call
is a sub-heap
of size 1. Now, working backwards, we can call
![]() for
each
for
each
![]() . This works, because by
the time we call
. This works, because by
the time we call
![]() , each of the two children of
, each of the two children of
![]() are the root of a sub-heap, so calling
are the root of a sub-heap, so calling
![]() makes
makes
![]() into the root of its own subheap.
into the root of its own subheap.
BinaryHeap(T[] a, Comparator<T> c) {
this.c = c;
this.a = a;
n = a.length;
for (int i = n/2-1; i >= 0; i--) {
trickleDown(i);
}
}
The interesting thing about this bottom-up strategy is that it is more
efficient than calling
![]()
![]() times. To see this, notice that,
for
times. To see this, notice that,
for
![]() elements, we do no work at all, for
elements, we do no work at all, for
![]() elements, we call
elements, we call
![]() on a subheap rooted at
on a subheap rooted at
![]() and whose height is one, for
and whose height is one, for
![]() elements, we call
elements, we call
![]() on a subheap whose height is two,
and so on. Since the work done by
on a subheap whose height is two,
and so on. Since the work done by
![]() is proportional to
the height of the sub-heap rooted at
is proportional to
the height of the sub-heap rooted at
![]() , this means that the total
work done is at most
, this means that the total
work done is at most
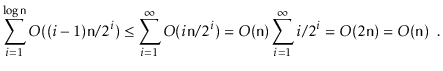
The following theorem describes the performance of
![]() .
.
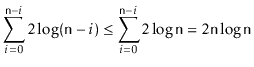
We have now seen three comparison-based sorting algorithms that each run
in
![]() time. By now, we should be wondering if faster
algorithms exist. The short answer to this question is no. If the
only operations allowed on the elements of
time. By now, we should be wondering if faster
algorithms exist. The short answer to this question is no. If the
only operations allowed on the elements of
![]() are comparisons, then no
algorithm can avoid doing roughly
are comparisons, then no
algorithm can avoid doing roughly
![]() comparisons. This is
not difficult to prove, but requires a little imagination. Ultimately,
it follows from the fact that
comparisons. This is
not difficult to prove, but requires a little imagination. Ultimately,
it follows from the fact that
We will start by focusing our attention on deterministic algorithms like
merge-sort and heap-sort and on a particular fixed value of
![]() . Imagine
such an algorithm is being used to sort
. Imagine
such an algorithm is being used to sort
![]() distinct elements. The key
to proving the lower-bound is to observe that, for a deterministic
algorithm with a fixed value of
distinct elements. The key
to proving the lower-bound is to observe that, for a deterministic
algorithm with a fixed value of
![]() , the first pair of elements that are
compared is always the same. For example, in
, the first pair of elements that are
compared is always the same. For example, in
![]() , when
, when
![]() is even, the first call to
is even, the first call to
![]() is with
is with
![]() and the
first comparison is between elements
and the
first comparison is between elements
![]() and
and
![]() .
.
Since all input elements are distinct, this first comparison has only
two possible outcomes. The second comparison done by the algorithm may
depend on the outcome of the first comparison. The third comparison
may depend on the results of the first two, and so on. In this way,
any deterministic comparison-based sorting algorithm can be viewed
as a rooted binary comparison tree.
Each internal node,
![]() ,
of this tree is labelled with a pair of indices
,
of this tree is labelled with a pair of indices
![]() and
and
![]() .
If
.
If
![]() the algorithm proceeds to the left subtree,
otherwise it proceeds to the right subtree. Each leaf
the algorithm proceeds to the left subtree,
otherwise it proceeds to the right subtree. Each leaf
![]() of this
tree is labelled with a permutation
of this
tree is labelled with a permutation
![]() of
of
![]() . This permutation represents the one that is
required to sort
. This permutation represents the one that is
required to sort
![]() if the comparison tree reaches this leaf. That is,
if the comparison tree reaches this leaf. That is,
The comparison tree for a sorting algorithm tells us everything about
the algorithm. It tells us exactly the sequence of comparisons that
will be performed for any input array,
![]() , having
, having
![]() distinct elements
and it tells us how the algorithm will reorder
distinct elements
and it tells us how the algorithm will reorder
![]() in order to sort it.
Consequently, the comparison tree must have at least
in order to sort it.
Consequently, the comparison tree must have at least
![]() leaves;
if not, then there are two distinct permutations that lead to the same
leaf; therefore, the algorithm does not correctly sort at least one of
these permutations.
leaves;
if not, then there are two distinct permutations that lead to the same
leaf; therefore, the algorithm does not correctly sort at least one of
these permutations.
For example, the comparison tree in Figure 11.6 has only
![]() leaves. Inspecting this tree, we see that the two input arrays
leaves. Inspecting this tree, we see that the two input arrays
![]() and
and ![]() both lead to the rightmost leaf. On the input
both lead to the rightmost leaf. On the input ![]() this leaf correctly outputs
this leaf correctly outputs
![]() . However, on the
input
. However, on the
input ![]() , this node incorrectly outputs
, this node incorrectly outputs
![]() .
This discussion leads to the primary lower-bound for comparison-based
algorithms.
.
This discussion leads to the primary lower-bound for comparison-based
algorithms.
Theorem 11.5 deals with deterministic
algorithms like merge-sort and heap-sort, but doesn't tell us anything
about randomized algorithms like quicksort. Could a randomized algorithm
beat the
![]() lower bound on the number of comparisons?
The answer, again, is no. Again, the way to prove it is to think
differently about what a randomized algorithm is.
lower bound on the number of comparisons?
The answer, again, is no. Again, the way to prove it is to think
differently about what a randomized algorithm is.
In the following discussion, we will assume that our decision
trees have been ``cleaned up'' in the following way: Any node that can not
be reached by some input array
![]() is removed. This cleaning up implies
that the tree has exactly
is removed. This cleaning up implies
that the tree has exactly
![]() leaves. It has at least
leaves. It has at least
![]() leaves
because, otherwise, it could not sort correctly. It has at most
leaves
because, otherwise, it could not sort correctly. It has at most
![]() leaves since each of the possible
leaves since each of the possible
![]() permutation of
permutation of
![]() distinct
elements follows exactly one root to leaf path in the decision tree.
distinct
elements follows exactly one root to leaf path in the decision tree.
We can think of a randomized sorting algorithm,
![]() , as a
deterministic algorithm that takes two inputs: The input array
, as a
deterministic algorithm that takes two inputs: The input array
![]() that should be sorted and a long sequence
that should be sorted and a long sequence
![]() of random real numbers in the range
of random real numbers in the range ![]() . The random numbers provide
the randomization for the algorithm. When the algorithm wants to toss a
coin or make a random choice, it does so by using some element from
. The random numbers provide
the randomization for the algorithm. When the algorithm wants to toss a
coin or make a random choice, it does so by using some element from ![]() .
For example, to compute the index of the first pivot in quicksort,
the algorithm could use the formula
.
For example, to compute the index of the first pivot in quicksort,
the algorithm could use the formula
![]() .
.
Now, notice that if we fix ![]() to some particular sequence
to some particular sequence ![]() then
then
![]() becomes a deterministic sorting algorithm,
becomes a deterministic sorting algorithm,
![]() , that has an associated comparison tree,
, that has an associated comparison tree,
![]() . Next, notice that if we select
. Next, notice that if we select
![]() to be a random
permutation of
to be a random
permutation of
![]() , then this is equivalent to selecting
a random leaf,
, then this is equivalent to selecting
a random leaf,
![]() , from the
, from the
![]() leaves of
leaves of
![]() .
.
Exercise 11.13 asks you to prove that, if we select
a random leaf from any binary tree with ![]() leaves, then the expected
depth of that leaf is at least
leaves, then the expected
depth of that leaf is at least ![]() . Therefore, the expected
number of comparisons performed by the (deterministic) algorithm
. Therefore, the expected
number of comparisons performed by the (deterministic) algorithm
![]() when given an input array containing a random
permutation of
when given an input array containing a random
permutation of
![]() is at least
is at least
![]() . Finally,
notice that this is true for every choice of
. Finally,
notice that this is true for every choice of ![]() , therefore it holds even for
, therefore it holds even for
![]() . This completes the proof of the lower-bound for randomized algorithms.
. This completes the proof of the lower-bound for randomized algorithms.
![\includegraphics[width=\textwidth ]{figs/mergesort}](img4068.png)
![\includegraphics[width=\textwidth ]{figs/mergesort-recursion}](img4098.png)
![\includegraphics[scale=0.90909]{figs/quicksort}](img4143.png)
![\includegraphics[width=\textwidth ]{figs/comparison-tree}](img4269.png)
![\includegraphics[width=\textwidth ]{figs/comparison-tree-b}](img4283.png)